Finding a better way to aggregate coal deposits
Getting seam aggregation right is critical for accurate estimation of tonnages, and easy and efficient scheduling for stratigraphic mines.
When working as a consultant I found many of the processes being used in coal aggregation relied on outdated software and complex manual scripting, and lacked auditability.
I worked on everything from life-of-mine to short-term scheduling and became very familiar with the industry standard software and methods.
Unfortunately a lot of the software was stuck in the 1990s because that’s when it had been developed. More products have entered the market recently, but many of them rely on the same basic, outdated concepts.
I’ve been noting some of the pitfalls in the way scheduling was approached, particularly around calculations of coal quantities and qualities and seam aggregation.
I often asked myself ‘How would I do this if I was writing my own software?’
So when I began my current technical services and product development role with Maptek, I had the ideal opportunity to expose my ideas and say ‘I know there is a better way of doing it’.
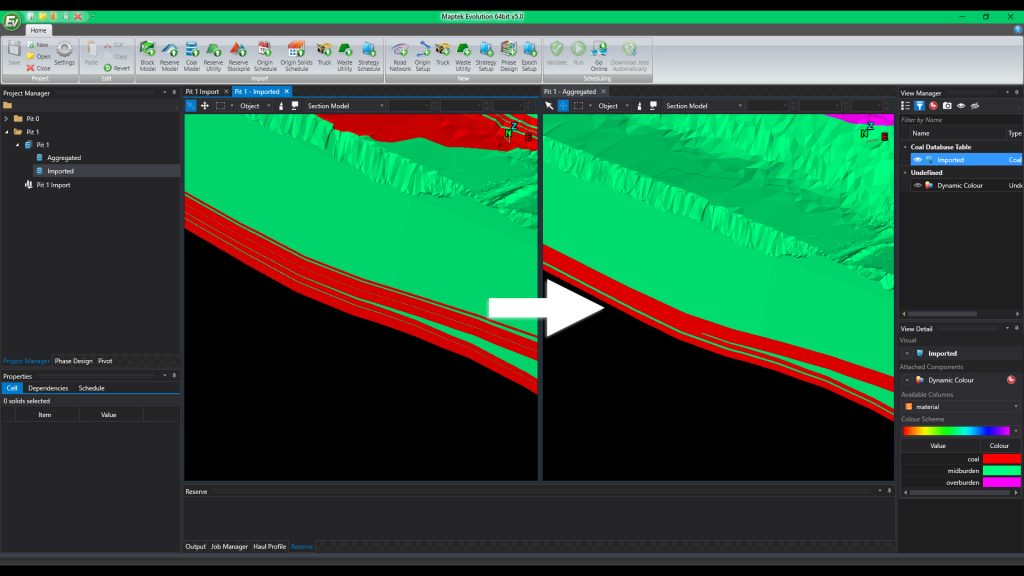
The Aggregation module takes coal geology from in-situ to ROM
With the new Aggregation module released in conjunction with Evolution 5, we’ve tried to address some of the shortcomings.
One of the biggest issues I found was the reliance on scripts without knowing what they were controlling.
People were responsible for writing, maintaining and checking their own scripts to calculate the coal model before scheduling. And they wouldn’t all be professional programmers so there’d be different levels of skill and the modelling exercise often became very messy, especially as different people added to, or changed, the scripts.
People would do their best to check the results generated by this scripting process, but coal models are complicated.
Apart from general high level checking, they were taking it on faith that everything had worked.
This data was then passed on to someone who has to make decisions based on it or sign off on a JORC report, which has legal ramifications if it’s wrong.
I had a strong sense that people were relying on numbers generated by a process which really had little safety net or auditability.
Our Aggregation module gives greater control and transparency over the figures and calculations.
The module takes an in-situ model and produces practical run-of-mine reserves and a flexible, yet automated, step-based workflow system which allows users to define relevant parameters.
Calculations happen automatically without the need for complex scripting and the module is designed to be fully auditable.
The Aggregation module stores the parameters, automated steps and scripts used with the final reserves model, so it is always clear how the model was created and what the inputs and assumptions were.
This ensures users will always have a full audit chain of the modelling process.
We’ve still retained the ability to use custom scripting, because every mine is different and needs to be able to tailor the model to its specific circumstances.
Now I’ve outlined a better, more auditable approach to data preparation, we can turn our focus to scheduling.
Find out more about the latest release of our strategic mine scheduling package Evolution here: www.maptek.com/news/intelligent-optimisation-approach-for-strategic-scheduling-control

